使用C++11实现SysY语言简单编译器
github: https://github.com/shenzuzhenwang/Complier-SysY
一、整体简介
使用架构:arm7ve
实现语言:C++
测试样例:SysY 2021,功能样例。全部通过
SysY 2021,性能样例。部分性能优化极大
词法分析:手工书写
语法分析:递归下降
AST:有,遍历AST生成IR
IR:三地址码、SSA、类LLVM的IR
总代码量:约10000行
优化:
- 常量折叠
- 死代码删除
- 只读全局转常量
- 只写变量移除
- 去除无用分支
- 基本块合并
- 循环不变量外提(参考)
- 公共子表达式删除(参考)
- 局部数组传播
- 常量数组全局化
主要参考:北航 早安!白给人and 《Efficient Construction of Static Single Assignment Form》
二、词法分析
定义了TokenInfo来代表每个token的类型,同时,还特别区分识别八进制、十进制、十六进制,与可能存在的溢出。
三、语法分析
首先,按照SysY的语法规则,定义了不同的节点类,并存在着继承关系
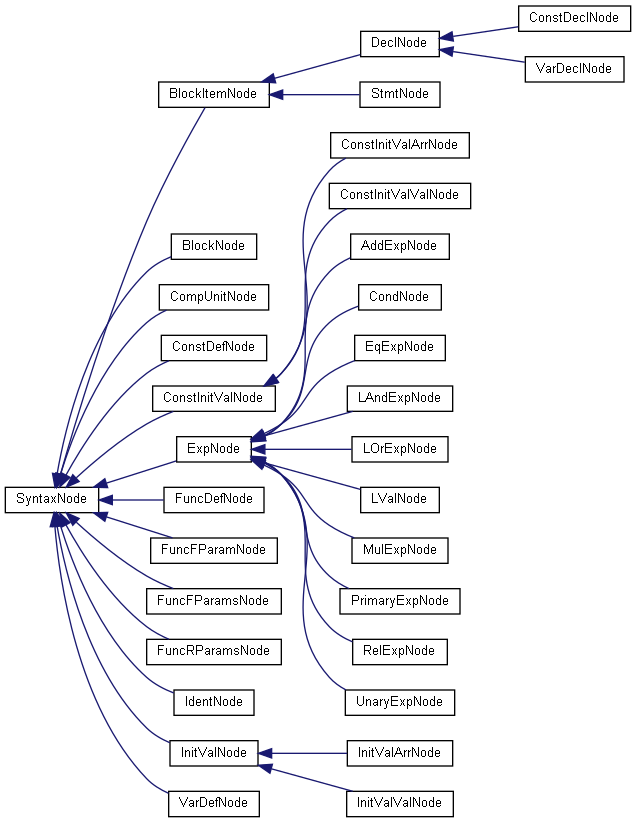
然后按照给定的语法,将会按照优先级,进行依次的递归下降分析,最后生成对应的AST节点
此外,还有symbolTable记录标识符名称,如函数名称,以及不同函数内的变量名称等
四、IR生成
IR的各类型节点继承图如下(类似LLVM的IR)
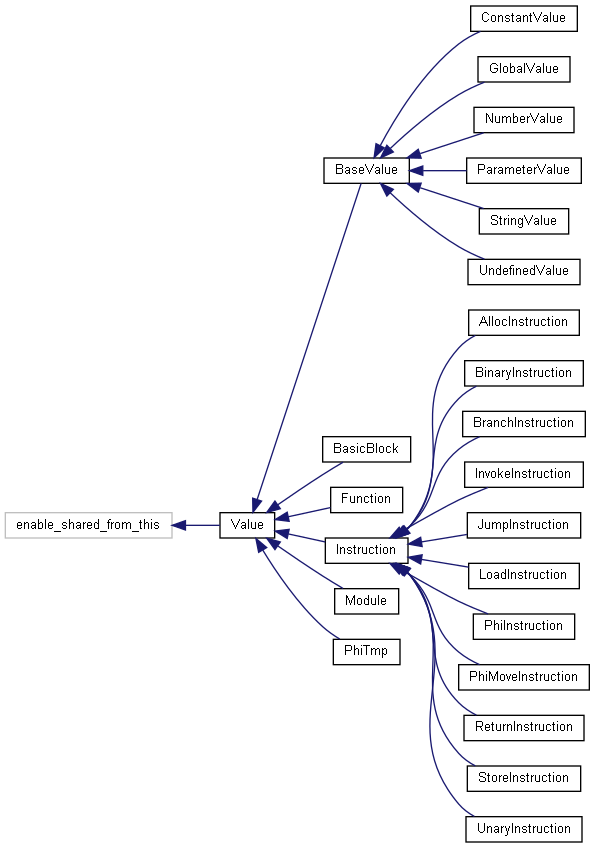
遍历之前生成的AST。
首先生成全局的变量GlobalValue与全局常量数组ConstantValue(全局常量直接替代)。
进入函数头,生成Function与入口BasicBlock,并记录函数参数ParameterValue。
blockToIr:之后进入函数体BLOCK,逐步分析,如果为局部变量,则定义VarDeclNode,并查看后面可能有的初始化值EXP;如果为语句,则
stmtToIr:判断语句的类型,ASSIGN则分析右值EXP;BLOCK则blockToIr;
IF与IF_ELSE则需要先分析条件conditionToIr,再生成每个可能的BasicBlock(包括ifStmt,elseStmt),并维护BasicBlock的前驱后继(ifStmt,elseStmt,endIf与当前的stmt,最后分析新生成的每个BasicBlock其中的语句stmtToIr;
WHILE先分析条件conditionToIr,再生成whileBody,whileJudge,whileEnd,preWhileBody等BasicBlock,并维护前驱后继,分析每个BasicBlock其中的语句stmtToIr,并记录循环深度
RETURN与BREAK则会直接改变WHILE中BasicBlock的前驱后继
conditionToIr:短路求值,依次递归分析LOrExpNode、LAndExpNode、EqExpNode(优先级依次递增),如果存在短路求值的情况,则会生成新的BasicBlock,并改变此BasicBlock的前驱后继,再继续分析conditionToIr
expToIr:分析不同情况的表达式,并将给表达式添加使用对象(之后会用)
五、SSA
SSA主要参考《Simple and Efficient Construction of Static Single Assignment Form》
对于每个基本块我们维护一个从每个源码变量到当前定义表达式的映射(map)。当对一个变量赋值时,我们记录 IR 的右边作为变量的当前定义。于是,当一个变量被读取时,我们查询它的当前定义
writeVariable(variable, block, value):
currentDef[variable][block] ← value
readVariable(variable, block):
if currentDef[variable] contains block:
# local value numbering
return currentDef[variable][block]
# global value numbering
return readVariableRecursive(variable, block)
局部值编号的实现在前驱块中查找一个值可能会导致进一步的递归查找。由于程序中有循环,可能导致无法终结的递归。因此在递归前,我们先创建没有操作数的 φ 函数并记录为基本块中的对应变量的当前定义。然后确定 φ 函数的操作数。如果递归查找回到了这个块中,这个 φ 函数将会提供一个定义并终止递归。
readVariableRecursive(variable, block):
if block not in sealedBlocks:
# 块不封闭,仅存在于循环体,此时可能前驱未加入完
val ← new Phi(block)
incompletePhis[block][variable] ← val
else if |block.preds| = 1:
# 优化只有一个前驱的情况:不需要 phi
val ← readVariable(variable, block.preds[0])
else:
# 如果有两个以上前驱块,用无操作数的 phi 破坏潜在的循环
val ← new Phi(block)
writeVariable(variable, block, val)
val ← addPhiOperands(variable, val)
writeVariable(variable, block, val)
return val
addPhiOperands(variable, phi):
# 从前驱中确定操作数
for pred in phi.block.preds:
# 递归向前驱块寻找同名变量的值,可能会由于循环,找到一样phi
phi.appendOperand(readVariable(variable, pred))
# 由于可能由于循环,phi的操作数的值为phi自己;或是两个操作数相同,此时需要去除phi
return tryRemoveTrivialPhi(phi)递归查找可能会留下冗余的 φ 函数,当且仅当它仅仅多次引用它自己和另一个值 v。这样一个 φ 函数能被移除并且用 v 代替它。
tryRemoveTrivialPhi(phi):
same ← None
# 操作数为自己和另一个值的时候,此phi可以用另一个值代替
for op in phi.operands:
if op = same || op = phi:
continue # 只有一个唯一值或引用自己
if same 6= None:
return phi # The phi merges at least two values: not trivial
same ← op
if same = None:
same ← new Undef() # phi 不可达或在开始块中
users ← phi.users.remove(phi) # 找出所有以这个 phi 为操作数的 φ 函数,除了它本身
phi.replaceBy(same) # 将所有用到 phi 的地方替代为 same 并移除 phi
# 尝试去递归移除用到 phi 的 φ 函数,因为它可能变得不重要(trivial)
for use in users:
if use is a Phi:
tryRemoveTrivialPhi(use)
return same如果一个基本块没有前驱会被添加进来,我们称这样的基本块是密封的(sealed)。只有被填满的块有后继,前驱总是被填满。注意一个密封的块不一定被填满。直观的说,一个被填满的块包含它所有的指令(instructions)和能给后继提供的变量定义。相反,当前驱都是已知时,一个被密封的块可以在它的前驱查询变量定义。
sealBlock(block):
# 在前驱查询变量定义 加入变量的phi可能值
for variable in incompletePhis[block]:
addPhiOperands(variable, incompletePhis[block][variable])
sealedBlocks.add(block)六、IR优化
1. 只读全局变量转为常数
先查看变量是否有被写入的可能,如果有使用store指令,或者全局数组被当做参数,则有写入的可能。
如果此全局变量没有被写入的可能,则将全局变量转换为常数,或者const array
2. 常量折叠
遍历每条IR,在二元操作中,如果两方都是常数,则直接得出结果;如果一方为特殊的常数(如0、1、-1等),则也可得出结果,或优化至仅一个操作数
在一元操作中,可以将多个一元操作简化。
在load操作中,可以直接提取const array中的常数。
3. 局部数组传播
记录数组被执行的操作,如果是store指令,且offset为常数,则记录目前对应位置的值;如果是load指令,且offset为常数,则查看有没有记录的值,有的话直接提取为常数;如果是其他操作,则清除之前记录的值(因为不知道数组是否改变,或改变了哪里)。
4. 只写变量清除
记录局部数组和全局变量被执行的操作,如果只有store而没有load,则去除此变量
5. 局部数组全局化
记录局部数组被执行的操作,如果其中只有store和load操作,且store的操作只有一次,offset和value均为常数,则将此局部数组转为const array
6. 循环不变量移除(参考)
对于每个函数,创建支配树,找到循环块,并找到block中的不动代码,最后插入有着循环不变量的块
7. 公共子表达式删除
对比两个指令的表达式是否相同(hashCode),以及对比相同表达式的两个值相同(equals),如果都一样,则变量直接替代即可
8. 去除无用分支
当分支条件为常数时,去除其中无用的分支块
9. 基本块合并
当某个基本块只有一个后继块时,可以去除掉跳转指令,并将后继块的phi指令移到此块,将两个块合并
10. 死代码删除
记录每个指令被使用的情况。
- 去除不被调用的函数(除main函数)
- 去除不被使用的全局变量
- 去除不用的块,先构建块的后继树,如果某个块没在后继树中,则此块不被使用
- 去除块不用的指令,如,有结果指令,但结果不被使用;调用的函数返回值不被使用,且函数无副作用(修改了自己范围之外的资源)
11. 基于图着色的寄存器分配(参考)
构建冲突图,标记每个变量活跃的时间,遍历每条指令,如果存在活跃值冲突,则加入冲突图表
最后分配物理寄存器,如果寄存器不足,无法解决冲突,则选取权重最小的变量,放入内存中,再次重新分配寄存器
七、汇编指令生成
首先,将全局变量放入.data中
之后,处理每个函数,加载形参(前四个在寄存器,四个之后放入图着色分配的寄存器),记录函数的返回地址,并分配栈上的空间,然后将函数的basicblock转换为汇编bbToMachineBB,此外,要向每个块前加label,每800指令,或在块的最后,加载一次全局变量
bbToMachineBB:
RET:保存返回值至R0,sp释放栈
BR:先进行比较,之后按比较进行跳转
JMP:直接跳转即可
INVOKE:先进行函数调用前的操作,传递参数,然后跳转至目标函数,最后重建上下文,记录返回的值
UNARY:执行取负(0-x)和取反(cmp值与0,相等则变为1,否则变为0)
BINARY:取余需要,先进行除法,在对结果进行三元乘减;比较指令需要通过mov指令加条件得到;乘除操作两个操作数需要均为寄存器;其余操作一个数可为立即数
CMP:通过mov指令加条件得到
LOAD:全局变量,基地址与偏移量已知,直接加载;局部数组,先计算相对sp偏移量,再进行加载
STORE:与LOAD类似
PHI:将phi的值移入对应的寄存器
立即数:先判断立即数是否合法,不合法需要mov
